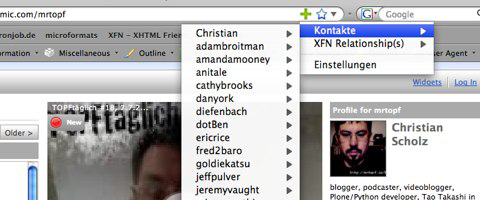
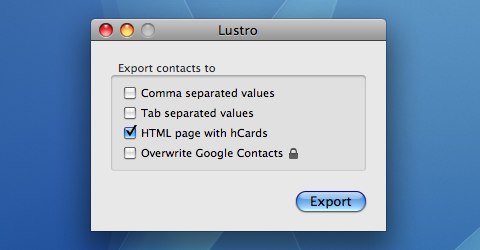
Seesmic scheint in nächster Zeit ne ganze Menge vor zu haben.
Auf dem Screenshot ist übrigens Mr. Topf zu sehen…
Der erste Schritt war wohl die Umstellung von reinem Flash zu mehr HTML, wahrscheinlich um Seesmic semantischer gestalten zu können (die ersten implementierten Formate sind XFN und hCards).
Aber das ist noch lange nicht alles, geplante sind unter anderem folgende Formate und offene Standards:
Open data formats: – RDF as the foundation, and exporters to microformats, HTML, RDFa… – We already use existing open metadata vocabularies – FOAF (for friend management) – SIOC (for community description) – Dublin Core for description of resources – In the process of using a subset of MPEG-7 ontology for video metadata.
Open identifiers: – Public URL scheme, and standardized authentication system. Considering the use of OpenID
Open source technologies: – Use Open Source projects wherever it’s possible. – Open Source critical pieces of the architecture, to allow for greater long term maintainability of complex pieces of software that are not core to the business and can benefit from the community.
Einfach dem dopplr-Vogel eine Freundschaftsanfrage schicken, dann eine Authentifizierungsnummer (bekommt man hier) schicken und warten bis dopplr bescheid gibt.
Danach kann man seinen neuen Standort bequem per d dopplr <Standort> oder @doppler <Standort> aktualisieren.
Das wäre ja schon schick genug, aber dopplr zeigt liebe zum Detail… Wird eine Location nicht gleich erkannt, wird sie archiviert, man bekommt per E-Mail bescheid:
Thanks for sending us a message by twitter.
Sorry, we weren’t able to extract enough information from your twitter to make a trip. We’ve archived it at http://www.dopplr.com/traveller/pfefferle/message/ne_lange_nummer
where you can create a trip by hand if you like.
Yours sincerely, The Dopplr Team.
…und man kann sie jederzeit (über dopplr) verbessern:
Wie schon im Lifestreamerwähnt, habe ich mir (um das Template nicht ändern zu müssen) ein simples six groups – Livecommunity WordPress-Plugin gebaut und vielleicht findet ja auch noch jemand anders Verwendung dafür… 🙂
EMAIL to ID ist ein Service, der eine E-Mail – Adresse zu OpenIDs macht.
Emailtoid is a simple mapping service that enables the use of email addresses as OpenID identifiers.
EMAIL to ID will kein neuer Provider sein, sondern sieht sich selbst nur als Übergangslösung bis E-Mail Services (z.B. GMX oder GMail) selbst diesen Dienst anbieten.
Der Login-Prozess soll folgendermaßen ablaufen:
When a user enters in an email address, there is an xrds discovery made on the top level domain (eg, gmail.com). If the XRDS document contains an Emailtoid mapper or email transformation template, use that. If not, then you make the same request on emailtoid.net to get the mapper document and send the email to there. Emailtoid is a fallback.
Wie genau das Mapping oder das XRDS-Dokument aussehen soll ist noch nicht spezifiziert, wird aber demnächst hier zu finden sein.
Macht eine E-Mail – Adresse als OpenID Sinn?
In Zukunft steht sicherlich die URL im Zentrum des Authentifizierungsprozesses, da sich über sie einfach mehr Informationen transportieren lassen (seien es Meta-Information oder Semantisches HTML). Auch das Semantische Web basiert auf URIs, um verschiedene Informationen zu vernetzen. Aus diesen Gründen sollte man den User mal so langsam an diese neuen Umstände gewöhnen 😉
Mit EMAIL to ID kann der Nutzer seine bestehenden Gewohnheiten (Anmelden per E-Mail – Adresse) beibehalten und trotzdem die Vorteile von OpenID nutzen (Simple Lösung für ein scheinbar schwieriges Problem… hat was vom Ei des Kolumbus).
Warum kein eigener Standard?
Ein neuer OpenID Standard auf Basis von E-Mail – Adressen (wie hier angedacht) würde zusätzlichen und unnötigen Implementierungsaufwand bedeuten (nimmt man an, die URLs sind die Zukunft), den man sich bei EMAIL to ID sparen kann. EMAIL to ID mappt eigentlich nur eine E-Mail – Adresse auf eine URL http://emailtoid.net/mapper?email=jane@example.com und entspricht somit einer vollwertigen OpenID (keine Anpassungen am bisherigen Standard nötig).
The momentum began building for ‚data portability‘ last year, and we are now at a point where there is strong support for the principle that users should be in control of their data and have the freedom to access it from across the web.
[…]
The goal of Portable Contacts is to make it easier for developers to give their users a secure way to access the address books and friends lists they have built up all over the web.
[…]
…we’re using existing standards wherever possible, including vCard, OpenSocial, XRDS-Simple, OAuth, etc.
Da spricht man von einheitlichen Standards und Portabilität, schafft es aber nicht, gemeinsam an einem Projekt zu arbeiten… Ich sehe kaum Erleichterung darin, statt verschiedener proprietärer APIs (z.B. Google’s GData Contacts API oder Microsoft’s Live Contacts API) wahrscheinlich mind. genauso viele unterschiedliche standard APIs (Data Portability oder Portable Contacts) implementieren zu müssen!
VIREL ist eine webseiten-freundliche Suchmaschine fuer microformats. VIREL sucht nach veroeffentlichten Informationen die als microformats in Webseiten eingebunden sind.
Ein schönes Feature ist der vCard-Export direkt über das Suchergebnis.
Leider müssen alle Seiten per Hand eingereicht werden, da es noch keinen z.B. Ping-Service gibt.
Mal schau’n wann telefonbuch.de in Zugzwang gerät 🙂
Vor ungefähr einem Monat habe ich schon einmal darüber geschrieben, wie wichtig Filter für Informationsmedien wie Feed-Reader oder Lifestreams sind. Der Artikel beschreibt, wie man Attention-Daten benutzen könnte um die enorme Informationsflut nach Interessen zu filtern.
NoiseRiver ist ein erster Versuch die Informationsmenge von FriendFeed durch einige Filter übersichtlicher zu gestalten.
You’re an addicted user of FriendFeed, and we understand you! isn’t it just so Magic!. NoiseRiver is not intended to replace FriendFeed, it’s an experimental service still in early alpha stage of developement that aims to extend friendFeed with some cool features like ranking on your interests and/or your feelings about other friendfeed’s users. Give it a try, login with your nickname and remote Key!
Für NoiseRiver ist keine separate Registrierung notwendig, man loggt sich einfach mit seinem FriendFeed-Username und dem API-Key ein und bekommt seinen unveränderten FF-Stream präsentiert.
Um diesen Stream leserlicher zu gestalten bietet NoiseRiver zwei Filter-Arten:
Nach Interessen filtern
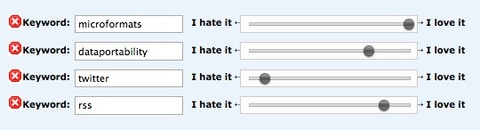
Über den Interessens-Filter hat der Nutzer die Möglichkeit seine Interessen als Keywords anzulegen und sie über einen Schieberegler zu gewichten.
Um Einträge mit einem speziellen Keyword komplett auszublenden, muss man den Schieberegler einfach nur komplett nach links ziehen und den Punkt „Hide entries with a very high hated rank? (-100%)“ aktivieren.
Diese Methode ist leider etwas umständlich, da man neben seinen Interessen auch all seine „Nicht-Interessen“ angeben muss, damit sie aus dem Stream verschwinden. Eleganter wäre ein Sortiermechanismus, nach Relevanz und Zeit, der alle Einträge die nicht zu den Interessen des Users gehören, einfach automatisch ausblendet.
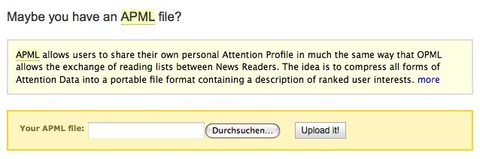
…natürlich habe ich sofort nach einer Möglichkeit gesucht um APML-Feeds zu importieren.
Leider gibt es nur einen Import per Upload (der auch noch nicht ganz funktioniert) und keine Möglichkeit einen APML-Feed direkt zu abonnieren.
Der Filter über Personen
Der Personen-Filter ist im Prinzip nichts anderes als der Interessens-Filter auf Basis von Nicknames.
Leider werden die Freunde von FF noch nicht in NoiseRiver übernommen und es gibt leider auch noch keine Möglichkeit sie z.B. per hCards zu importieren.
Bisher wird auch bei diesem Filter nicht nach Relevanz sortiert. Die Einträge werden lediglich farblich gekennzeichnet.
Fazit
Der Service ist sicherlich nicht ausgereift und braucht noch einige Zeit um ein wirkliches Relevance-Ranking anbieten zu können, spart durch das Ausblenden und Hervorheben von Einträgen jetzt schon eine Menge Zeit beim Lesen.
In dem Artikel Use the new microformats API in your Firefox 3.0 Extensions beschreibt Rob Crowther wie man mit Hilfe der Firefox-Microformats-API eine hCard speichert um sie zum Ausfüllen verschiedener Formulare weiterverwenden zu können.
Das Problem: Das Prinzip funktioniert leider nur bei Formularen die dem festgelegten Aufbau entsprechen. Im Fall des Beispiels wäre das:
Das Einheitliche Format für Ein- (Formular) und Ausgabe (Microformats) hätte zur Folge, dass keine aufwendigen Mapper (wie z.B. hCard-Mapper) mehr nötig wären um ein Formular per hCard auszufüllen…
[…] if you’ve got at least a 1 GB USB drive and a computer that can boot from it, you’re in luck. LiveXBMC, a blend of the XBMC and Ubuntu Linux, lets you do all the same big-screen media playing, […] and other media center goodness without installing a thing, but with saved settings.