Martin McEvoy von WebOrganics hat gerade den Microformats Transformrangekündigt. Die Daseinsberechtigung des Transformr neben Optimus, dem Chef-Transformer (ich hoffe die Transformers sind euch ein Begriff 🙂 ), ist die umfassende hAudio-Unterstützung, was wohl daran liegt dass Martin McEvoy aktiv an diesem Standard mitarbeitet.
hAudio Features:
hAudio to RSS
hAudio to RSS2
hAudio to XSPF
XSPF („spiff“) steht für XML Shareable Playlist Format und ist ein offener XML-Standard für Playlisten.
Ein weiteres interessantes Feature ist hFoaF welches hCards und XFN in FoaF wandelt.
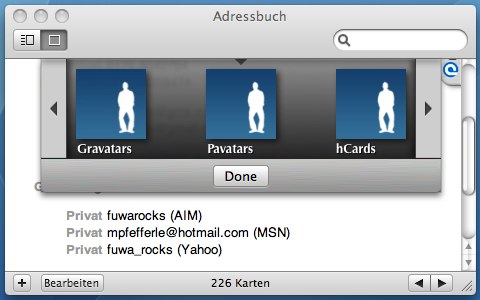
Avatars ist ein kleines Plugin für das Address Book (Mac) um die Profilbilder der Kontakte per Gravatar, Pavatar oder hCard-Photo zu vervollständigen. Nach der Installation ist das Plugin über »Visitenkarte > Download Custom Image« erreichbar und versucht anhand der E-Mail – Adressen ein Gravatar und anhand der URLs ein Pavatar oder ein hCard-Photo zu finden.
Großartige Idee 🙂
Ein anderes schickes Tool um hCards in das Address Book zu importieren (welches ich schon vor einiger Zeit vorgestellt hatte) ist übrigens der vCard Explorer.
SMOB is a distributed / decentralised microblogging system built on RDF and Semantic Web technologies, mainly SIOC and FOAF. Currently, we have simple prototypes of a publishing and an aggregating service, less than 100 lines of PHP code each.
Gerade nach den Pressemeldungen über MySpaces „Data Availability“:
[…] MySpace is announcing a broad ranging embrace of data portability standards today, along with data sharing partnerships with Yahoo, Ebay, Twitter and their own Photobucket subsidiary. […] #
…oder über Googles „Friend Connect“:
As we reported on Friday, Google will be launching its own data portability effort called Friend Connect. […] #
…ist (meiner Meinung nach) einer der treffendsten Punkte in Chris‘ Kommentar:
The behavior indicates […] that the DP-PR machine is simply more effective at taking credit for big moves that they had nothing directly to do with than to promote smaller independent, more „grassroots“ groups who are *actually* making moves towards effective data portability, like Dopplr, like TripIt, like Satisfaction and Twitter and the rest. I don’t believe I’ve seen any press releases go out about them, and yet I would consider them to be on the vanguard giving people access to their data in real-world, useful ways.
Ich muss Chris Messina leider recht geben, keines der groß angekündigten (und mit DataPortability in Verbindung gebrachten) Systeme betreibt wirklich DataPortability (zumindest zum aktuellen Zeitpunkt). Sowohl MySpace als auch Google verwenden zwar offene Standards (Facebook nutzt sogar keinen der erwähnten Standards für „Facebook Connect“) wie OAuth oder OpenID, aber bisher leider nur hinter ihren „Walled Gardens„. Was ist mit den wahren DP „Helden“ wie Dopplr, Magnolia oder Satisfaction, die wirkliche Anwendungsfälle schaffen und sich dem Ziel der portablen Daten Schritt für Schritt nähern?
Carsten Pötter beschreibt das bestehende Problem auch noch einmal von einer etwas anderen Seite:
DataPortability, Data Availability, Facebook Connect, Google Friend Connect, DiSo,… […] All the mentioned initiatives just lead to confusion. We can’t be sure if we mean the same thing when talking about data portability anymore. It’s probably best to abandon that term and just focus on single issues. Can I export my profile or can it just be accessed by a third party?
Da genießt man einmal ein internetfreies Pfingst-Wochenende und alleWelt macht DataPortability (naja, fast)… Das heißt, ich werde die nächsten Tage ne Menge zu lesen haben und sicherlich auch bald meinen Senf dazu geben 😉
Ich kann diese Kritikpunkte zwar nachvollziehen, bin aber dennoch der Meinung dass es auch für die aktuelle Form des Attention-XMLs einige Anwendungs-Szenarien gibt, die ich hier beschreiben möchte…
Die Informationsflut im Internet wird immer größer und schneller, wie Herr Scoble in seinem Artikel „The noise reduction system“ sehr treffend bemerkt:
Oh, the glorious noise! Everyone loves beating me up for causing the noise. No, I am not the cause. I pass it along. You should see my inbound streams. Every second or two a new Twitter is aimed at me. Every few seconds, a new blog post comes into Google Reader. Every few seconds, a new thing on FriendFeed.
Der Artikel ist auf alle Fälle lesenswert und beschreibt auch einige Lösungsansätze, auf die ich aber nicht weiter eingehen möchte. Was ich viel interessante finde ist, dass APML genau der richtige Filter für dieses Signal-Noise-Ratio – Problem ist.
APML als News-Filter
Einer der Themen in Scobles Beitrag ist die enorme Flut von Informationen/News die täglich in seinem News-Reader auflaufen. Um diesem Problem Herr zu werden bräuchte man einen Filter, der selbstständig entscheidet was für ihn relevant ist und was nicht.
Ein APML-File bietet alles was für einen einfachen Filter notwendig ist:
Eine Gewichtung meiner Interessen
Eine einfache Struktur
URLs/Feeds die ich bevorzuge
Mit diesen Informationen sollte es doch recht einfach möglich sein, die Neuigkeiten die in (z.B.) meinem Feed-Reader auflaufen zu bewerten und mir einen (ausgewählten) News-Stream zu präsentieren. So zusagen ein Spam-Filter für News (und einem Spam-Filter sind wir ja auch nicht böse wenn mal eine Mail durchrutscht, weil er uns doch ne ganze menge Arbeit erspart).
Da es sich bei diesem Filter nur um ein optionales Feature handelt, bleibt es dem Nutzer selbst überlassen welcher Art des Informations-Konsums er frönen will.
NewsGator, einer der führenden Feed-Reader Anbieter, hat auch schon einige Schritte in diese Richtung angekündigt und bietet bei einigen seiner Produkte auch schon ein paar APML-Funktionalitäten an.
APML als Kommunikations-Filter
Der andere angesprochene Punkt ist die Kommunikation verursacht durch Microblogging-Dienste wie Twitter, Jaiku oder FriendFeed. Will man diese aktiv verfolgen ist es nahezu unmöglich nebenher noch einer normalen Tätigkeit nach zu gehen.
Um noch einmal Herrn Scoble zu zitieren:
The problem? Twitter and FriendFeed have brought new noise into our lives (at least for the early adopter types) and there aren’t good ways to reduce the noise.
But FriendFeed shows us a way out. How about seeing only posts that have at least two “likes?” Isn’t that a way to reduce the noise? Yes! […]
Auch hier würde ein Filter in Form meiner Attention-Daten den Kommunikations-Stream enorm reduzieren. Wenn Auszeichnungen wie #hashtags weiter Verbreitung finden sollte es nicht schwer sein, diese mit meinen Attention-Tags zu vergleichen und zu bewerten. Selbst ohne #hashtags ist es immer noch möglich, den Inhalt (sind ja nur 140 Zeichen) mit den Interessen abgleichen.
Im nächsten Schritt könnte man den User (ähnlich wie bei Facebook) entscheiden lassen, welches Ranking die Inhalte mindestens haben müssen um angezeigt zu werden.
Ich denke gerade bei diesen zwei Anwendungsbeispiele ist die einfache XML-Struktur eher ein Vorteil als ein Nachteil. Das Ranking sollte schnell und unkompliziert funktionieren und es sollte auch kein Problem sein, wenn eine Information durch diesen Filter rutschen sollte.
In den letzten Tagen wurde in der Microformats-Community viel über das Thema standardisiertes Parsen und einheitliches Darstellen der verschiedenen Mikroformate (hCard im speziellen) diskutiert.
Leider gab es bisher keinen einheitlichen „Microformats-Acid-Tests“ sondern nur vereinzelte (projektspezifische) Seiten um einige Spezialfälle zu testen.
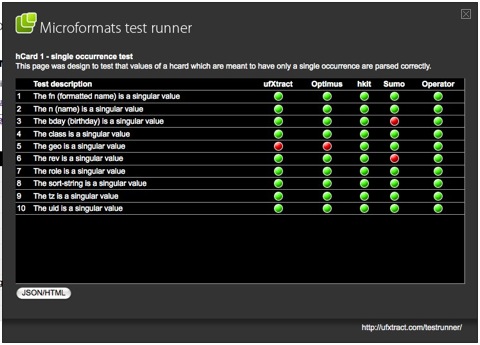
Glenn Jones, einer der Macher von ufXtract hat jetzt eine sehr schöne Microformats-Testsuite erstellt, die parser-unabhängig funktionieren soll um eventuelle Interpretationsfehler erkennen und vergleichen zu können.
The Testrunner
Um die Tests so einfach wie möglich zu gestalten, hat Glenn einen einen JavaScript-Testrunner entwickelt (siehe Screenshot). Testen kann man den Runner unter z.B. http://ufxtract.com/testsuite/hcard/1.0/hcard1.htm in dem man einfach Alt + X drückt (CTRL + ALT + X auf dem Mac).
Hier sei nochmal erwähnt warum es so wichtig ist, dass jeder Parser das gleiche (micro)JSON-Format nutzt:
Please note that at this stage the JSON standardisation process can cause a test to be marked as failed when it could be judged to have passed. #
Nur bei einer gleichen JSON-Struktur kann der Output sinnvoll verglichen werden. Eine erste Version der jCard (danke nochmal an Gordon Oheim für sein Engagement) findet man im Microformats-Wiki.
Testsuite-API
Wer die Testsuite für seinen eigenen Parser einsetzen will, sollte sich mal die Testsuite-API zu Gemüte führen.
Rather than just build something in isolation I thought it would be nice to find a way to share this work with the community. #