Einfach dem dopplr-Vogel eine Freundschaftsanfrage schicken, dann eine Authentifizierungsnummer (bekommt man hier) schicken und warten bis dopplr bescheid gibt.
Danach kann man seinen neuen Standort bequem per d dopplr <Standort> oder @doppler <Standort> aktualisieren.
Das wäre ja schon schick genug, aber dopplr zeigt liebe zum Detail… Wird eine Location nicht gleich erkannt, wird sie archiviert, man bekommt per E-Mail bescheid:
Thanks for sending us a message by twitter.
Sorry, we weren’t able to extract enough information from your twitter to make a trip. We’ve archived it at http://www.dopplr.com/traveller/pfefferle/message/ne_lange_nummer
where you can create a trip by hand if you like.
Yours sincerely, The Dopplr Team.
…und man kann sie jederzeit (über dopplr) verbessern:
Wie schon im Lifestreamerwähnt, habe ich mir (um das Template nicht ändern zu müssen) ein simples six groups – Livecommunity WordPress-Plugin gebaut und vielleicht findet ja auch noch jemand anders Verwendung dafür… 🙂
EMAIL to ID ist ein Service, der eine E-Mail – Adresse zu OpenIDs macht.
Emailtoid is a simple mapping service that enables the use of email addresses as OpenID identifiers.
EMAIL to ID will kein neuer Provider sein, sondern sieht sich selbst nur als Übergangslösung bis E-Mail Services (z.B. GMX oder GMail) selbst diesen Dienst anbieten.
Der Login-Prozess soll folgendermaßen ablaufen:
When a user enters in an email address, there is an xrds discovery made on the top level domain (eg, gmail.com). If the XRDS document contains an Emailtoid mapper or email transformation template, use that. If not, then you make the same request on emailtoid.net to get the mapper document and send the email to there. Emailtoid is a fallback.
Wie genau das Mapping oder das XRDS-Dokument aussehen soll ist noch nicht spezifiziert, wird aber demnächst hier zu finden sein.
Macht eine E-Mail – Adresse als OpenID Sinn?
In Zukunft steht sicherlich die URL im Zentrum des Authentifizierungsprozesses, da sich über sie einfach mehr Informationen transportieren lassen (seien es Meta-Information oder Semantisches HTML). Auch das Semantische Web basiert auf URIs, um verschiedene Informationen zu vernetzen. Aus diesen Gründen sollte man den User mal so langsam an diese neuen Umstände gewöhnen 😉
Mit EMAIL to ID kann der Nutzer seine bestehenden Gewohnheiten (Anmelden per E-Mail – Adresse) beibehalten und trotzdem die Vorteile von OpenID nutzen (Simple Lösung für ein scheinbar schwieriges Problem… hat was vom Ei des Kolumbus).
Warum kein eigener Standard?
Ein neuer OpenID Standard auf Basis von E-Mail – Adressen (wie hier angedacht) würde zusätzlichen und unnötigen Implementierungsaufwand bedeuten (nimmt man an, die URLs sind die Zukunft), den man sich bei EMAIL to ID sparen kann. EMAIL to ID mappt eigentlich nur eine E-Mail – Adresse auf eine URL http://emailtoid.net/mapper?email=jane@example.com und entspricht somit einer vollwertigen OpenID (keine Anpassungen am bisherigen Standard nötig).
VIREL ist eine webseiten-freundliche Suchmaschine fuer microformats. VIREL sucht nach veroeffentlichten Informationen die als microformats in Webseiten eingebunden sind.
Ein schönes Feature ist der vCard-Export direkt über das Suchergebnis.
Leider müssen alle Seiten per Hand eingereicht werden, da es noch keinen z.B. Ping-Service gibt.
Mal schau’n wann telefonbuch.de in Zugzwang gerät 🙂
Vor ungefähr einem Monat habe ich schon einmal darüber geschrieben, wie wichtig Filter für Informationsmedien wie Feed-Reader oder Lifestreams sind. Der Artikel beschreibt, wie man Attention-Daten benutzen könnte um die enorme Informationsflut nach Interessen zu filtern.
NoiseRiver ist ein erster Versuch die Informationsmenge von FriendFeed durch einige Filter übersichtlicher zu gestalten.
You’re an addicted user of FriendFeed, and we understand you! isn’t it just so Magic!. NoiseRiver is not intended to replace FriendFeed, it’s an experimental service still in early alpha stage of developement that aims to extend friendFeed with some cool features like ranking on your interests and/or your feelings about other friendfeed’s users. Give it a try, login with your nickname and remote Key!
Für NoiseRiver ist keine separate Registrierung notwendig, man loggt sich einfach mit seinem FriendFeed-Username und dem API-Key ein und bekommt seinen unveränderten FF-Stream präsentiert.
Um diesen Stream leserlicher zu gestalten bietet NoiseRiver zwei Filter-Arten:
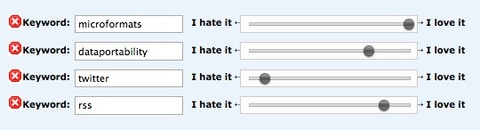
Nach Interessen filtern
Über den Interessens-Filter hat der Nutzer die Möglichkeit seine Interessen als Keywords anzulegen und sie über einen Schieberegler zu gewichten.
Um Einträge mit einem speziellen Keyword komplett auszublenden, muss man den Schieberegler einfach nur komplett nach links ziehen und den Punkt „Hide entries with a very high hated rank? (-100%)“ aktivieren.
Diese Methode ist leider etwas umständlich, da man neben seinen Interessen auch all seine „Nicht-Interessen“ angeben muss, damit sie aus dem Stream verschwinden. Eleganter wäre ein Sortiermechanismus, nach Relevanz und Zeit, der alle Einträge die nicht zu den Interessen des Users gehören, einfach automatisch ausblendet.
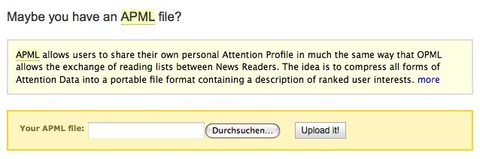
…natürlich habe ich sofort nach einer Möglichkeit gesucht um APML-Feeds zu importieren.
Leider gibt es nur einen Import per Upload (der auch noch nicht ganz funktioniert) und keine Möglichkeit einen APML-Feed direkt zu abonnieren.
Der Filter über Personen
Der Personen-Filter ist im Prinzip nichts anderes als der Interessens-Filter auf Basis von Nicknames.
Leider werden die Freunde von FF noch nicht in NoiseRiver übernommen und es gibt leider auch noch keine Möglichkeit sie z.B. per hCards zu importieren.
Bisher wird auch bei diesem Filter nicht nach Relevanz sortiert. Die Einträge werden lediglich farblich gekennzeichnet.
Fazit
Der Service ist sicherlich nicht ausgereift und braucht noch einige Zeit um ein wirkliches Relevance-Ranking anbieten zu können, spart durch das Ausblenden und Hervorheben von Einträgen jetzt schon eine Menge Zeit beim Lesen.
In dem Artikel Use the new microformats API in your Firefox 3.0 Extensions beschreibt Rob Crowther wie man mit Hilfe der Firefox-Microformats-API eine hCard speichert um sie zum Ausfüllen verschiedener Formulare weiterverwenden zu können.
Das Problem: Das Prinzip funktioniert leider nur bei Formularen die dem festgelegten Aufbau entsprechen. Im Fall des Beispiels wäre das:
Das Einheitliche Format für Ein- (Formular) und Ausgabe (Microformats) hätte zur Folge, dass keine aufwendigen Mapper (wie z.B. hCard-Mapper) mehr nötig wären um ein Formular per hCard auszufüllen…
Die Ankündigung der BBC, alle Microformats die auf den abbr-design-pattern aufbauen, zu entfernen und sich in der Zwischenzeit mit dem Thema RDFa zu beschäftigen…
In the meantime we’ll be looking at the possible use of RDFa (a slightly bigger S semantic web technology similar to microformats but without some of the more unexpected side-effects).
…wurde von einigen Personen als direkter vergleich zwischen den beiden Formate (zugunsten von RDFa) gesehen und hat eine hitzige Diskussion entfacht.
Am interessantesten ist jedoch die Antwort der BBC auf dieses „Missverständnis“:
My original post on removing microformats from /programmes seems to have kicked off quite a debate. Unfortunately some of this seems to have resulted in RDFa people criticising microformats and vice versa. Which wasn’t really the intention.
…und dass das Entfernen der abbr-design-pattern auch nur temporärer Natur ist, bis das Problem behoben wurde:
This is hopefully only a temporary ban until the microformats community come up with an alternative to the abbreviation design pattern that doesn’t break BBC accessibility standards.
Also… viel Aufregung um nichts…
Ich persönlich verstehe die Diskussion (Microformats vs. RDFa) nicht wirklich und kann mich eigentlich nur Evan Prodromou anschließen, der folgendes als Idealfall ansieht:
RDFa gets acknowledged and embraced by microformats.org as the future of semantic-data-in-XHTML
The RDFa group makes an effort to encompass existing microformats with a minimum of changes
microformats.org leaders join in on the RDFa authorship process
microformats.org becomes a focus for developing real-world RDFa vocabularies
Dass die abbr-design-pattern nicht das gelbe vom Ei sind (massive Probleme mit Screen-Readern), hat das Web Standards Project (WaSP) schon vor mehr als einem Jahr festgestellt, aber es bedarf meistens etwas Druck von außen damit sich wirklich etwas ändert.
Fire Eagle is a site that stores information about your location. With your permission, other services and devices can either update that information or access it. By helping applications respond to your location, Fire Eagle is designed to make the world around you more interesting!
Man kann Fire Eagle natürlich auch über ein Webfrontend oder per Dopplr/Places aktualisieren… aber das kann ja jeder 🙂
Der twitter-firebot
Um den Fire-Bot testen zu können muss man ihm zuerst folgen und ihn um eine Einladung bitten (falls man noch keinen Invite hat).
d firebot invite
Nach der Einladung erfolgt die Authentifizierung des Bots.
d firebot auth
Der Bot antwortet (mir hat er leider noch nicht geantwortet) mit einem Authentifizierungs-Link über welchen der Firebot für Fireeagle freischaltet wird.
Danach kann man seine Location bequem über Twitter ändern:
Die Jungs von #geo haben sich einen ganz ähnlichen Fireeagle-Bot für ihren Channel gebaut.
Nachdem man den Bot auf sich aufmerksam gemacht hat…
[19:02] pfefferle: fireup, help?
[19:02] fireeagle: pfefferle: I have just sent you a URL in privmsg, please click on it to authorize.
…bekommt man eine Private-Message mit einer Authentifizierungs-URL…
fireeagle: Try Again! You must authorize first: https://fireeagle.yahoo.net/oauth/authorize?oauth_token=XXXXX
…(gleiches Prinzip wie bei Twitter) und man kann seinen Status auch über IRC ändern.
[19:23] pfefferle: fireup Weinheim, Germany
[19:23] fireeagle: Updating pfefferle to Weinheim, Deutschland
Zur Kontrolle nochmal im Fire Eagle nachschaun:
Fire Eagle last spotted you about 1 hour ago in Weinheim, Deutschland using Fire Eagle GeoIRC bot. If you’ve gone somewhere else, then you should update your location!