Christian Scholz macht sich in seinem Artikel „The OpenID Branding problem“ Gedanken darüber wie man dem normalen User OpenID näher bringen könnte (und ich Stimme ihm auch bei vielen Punkten zu (der ID-Selector ist wirklich sehr überladen)).
Aber ist es wirklich wichtig am Branding „OpenID“ zu arbeiten? Yahoo hat in seiner OpenID Usability Studie einen Satz, der das Problem (meiner Meinung nach) ziemlich gut trifft:
„Promote the utility, not the technology“
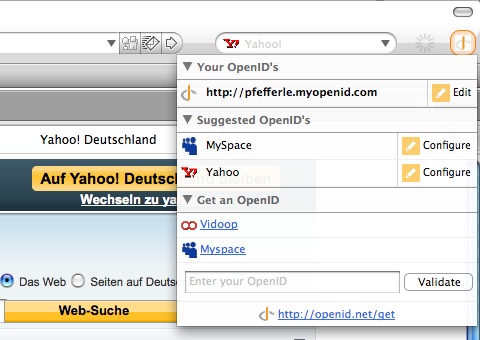
Als Google seine OpenID Implementierung veröffentlicht hat wurden viele Stimmen laut, Google würde OpenID nur für seine Zwecke „missbrauchen“… Aber ist das nicht genau der Schritt den OpenID gehen muss? Weg von der Technik und dem Branding, hin zur Funktionalität und dem Anbieter. Facebook Connect ist doch nur so erfolgreich (wobei wir das ja noch gar nicht wissen) weil ein normaler Internet-Nutzer den Login wieder erkennt (E-Mail Adresse und Passwort) und versteht… bei Yahoo!s oder Googles Directed Identity Implementierung ist es ähnlich, der Benutzer klickt einen Link wie z.B. „mit Google Account anmelden“ kommt zu Google und muss wieder nur das Formular ausfüllen welches er schon kennt. Er bekommt nichts von OpenID mit und hat sich ohne Hürden und (im besten Fall) mit einem Klick angemeldet… und für alle Geeks bleibt immer noch die normale OpenID Anmledung!
Diesen Schritt finde ich sogar noch Sinnvoller als die E-Mail – OpenID, da der Nutzer ohne große Workarounds (und nichts anderes ist EAUT) auf OpenID vorbereitet wird.
Ich würde mich sehr über einige weitere Meinungen und Ideen freuen, also ran an die Tastatur 😉
Dieser Post entstand übrigens als Kommentar bei hackr