Ich schreibe gerade einen Artikel für das t3n Magazin über aktuelle Sign-In-Mechanismen und hab mir in dem Zuge BrowserID mal etwas genauer angeschaut. Ich bin wirklich extrem überrascht mit wie wenig Arbeit es sich in z.B. WordPress einbauen lässt.
BrowserID besteht eigentlich nur aus einem JS-File,ein paar Zeilen JS-Code:
<script src="https://browserid.org/include.js" type="text/javascript"></script>
<script type="text/javascript">
navigator.id.get(function(assertion) {
if (assertion) {
// This code will be invoked once the user has successfully
// selected an email address they control to sign in with.
} else {
// something went wrong! the user isn't logged in.
}
});
</script>Code-Sprache: HTML, XML (xml)und dem anschließenden Verifizieren der assertion:
$ curl -d "assertion=&audience=https://mysite.com" "https://browserid.org/verify"
{
"status": "okay",
"email": "lloyd@example.com",
"audience": "https://mysite.com",
"expires": 1308859352261,
"issuer": "browserid.org"
}Code-Sprache: JavaScript (javascript)Den ausführlichen Ablauf der Authentifizierung findet ihr auf Github.
Um BrowserID in WordPress zu integrieren lädt man also zuerst den JS-Code in den Login Header:
// add the BrowserID javascript-code to the header
add_action('login_head', 'bi_add_js_header');
function bi_add_js_header() {
echo '<script src="https://browserid.org/include.js" type="text/javascript"></script>';
echo '<script type="text/javascript">'."\n";
echo 'function browser_id_login() {
navigator.id.get(function(assertion) {
if (assertion) {
window.location="' . get_site_url(null, '/') .'?browser_id_assertion=" + assertion;
} else {
// do nothing!
}
})
};'."\n";
echo '</script>';
}Code-Sprache: PHP (php)und platziert den BrowserID-Button auf der Login-Seite:
// add the login button
add_action('login_form', 'bi_add_button');
function bi_add_button() {
echo '<p><a href="#" onclick="return browser_id_login();"><img src="https://browserid.org/i/sign_in_blue.png" style="border: 0;" /></a></p>';
}Code-Sprache: HTML, XML (xml)Nach dem klick auf den Button öffnet sich das Autorisierungs-Fenster von BrowserID und nach dem erfolgreichen Sign-In wird die gerade implementierte Methode navigator.id.get(function(assertion) {} aufgerufen.
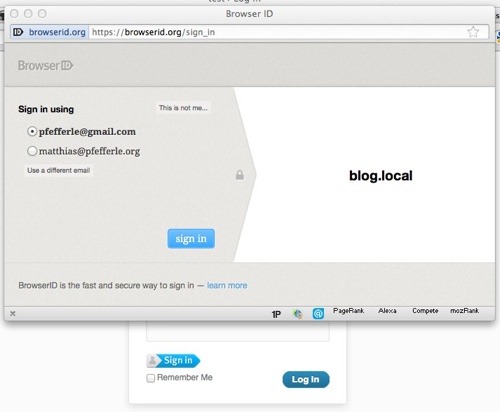
Im nächsten Schritt muß man die erhaltene assertion über BrowserID.org verifizieren. Da ich den notwendigen POST nicht über JavaScript absetzen will, leite ich einfach auf eine Seite weiter und übergebe die erhaltene assertion als GET-Paramater.
if (assertion) {
window.location="' . get_site_url(null, '/') .'?browser_id_assertion=" + assertion;
}Code-Sprache: JavaScript (javascript)Jetzt kann der POST bequem über WordPress abgesetzt werden.
// the verification code
add_action('parse_request', 'bi_verify_id');
function bi_verify_id() {
global $wp_query, $wp, $user;
if( array_key_exists('browser_id_assertion', $wp->query_vars) ) {
// some settings for the post request
$args = array(
'method' => 'POST',
'timeout' => 30,
'redirection' => 0,
'httpversion' => '1.0',
'blocking' => true,
'headers' => array(),
'body' => array(
'assertion' => $wp->query_vars['browser_id_assertion'], // the assertion number we get from the js
'audience' => "http://".$_SERVER['HTTP_HOST'] // the server host
),
'cookies' => array(),
'sslverify' => 0
);
// check the response
$response = wp_remote_post("https://browserid.org/verify", $args);
if (!is_wp_error($response)) {
$bi_response = json_decode($response['body'], true);
// if everything is ok, check if there is a user with this email address
if ($bi_response['status'] == 'okay') {
$userdata = get_user_by('email', $bi_response['email']);
if ($userdata) {
$user = new WP_User($userdata->ID);
wp_set_current_user($userdata->ID, $userdata->user_login);
wp_set_auth_cookie($userdata->ID, $rememberme);
do_action('wp_login', $userdata->user_login);
wp_redirect(home_url());
exit;
} else {
// show error when there is no matching user
echo "no user with email address '" . $bi_response['email'] . "'";
exit;
}
}
}
// show error if something didn't work well
echo "error logging in";
exit;
}
}Code-Sprache: PHP (php)Gibt es einen User mit der entsprechenden E-Mail – Adresse wird er eingeloggt, falls nicht, wird ein Fehler ausgegeben.
Bei der Demo hab ich mir aus Zeitgründen ein wenig Code bei Marcel Bokhorst geliehen, dessen BrowserID-Plugin wesentlich ausgereifter und vollständiger ist als der kleine Demo-Code den ich hier zusammengestückelt habe.
Wenn euch das zu schnell ging und ich auf einige Details nicht genügend eingegangen bin, könnt ihr gerne fragen 🙂
Ich habe den kompletten Code übrigens auch auf Github hochgeladen… das ist einfacher als sich alles zusammen zu kopieren.

