Beim „basteln“ an SemPress, meinem ersten WordPress Theme, habe ich das erste Mal praktische Erfahrungen mit Schema.org gesammelt und mir sind vor allem zwei Dinge klar geworden: 1. Warum Schema.org nach einer Art „Vererbungs“-Prinzip aufgebaut ist und 2. Wie Google mit Schema.org umgeht.
The http://schema.org/Thing
Das „einfachste“ Schema ist ein „Thing“ und hat folgende Attribute:
description | TEXT | A short description of the item. |
|---|---|---|
image | URL | URL of an image of the item. |
name | TEXT | The name of the item. |
url | URL | URL of the item. |
Da alle anderen Objekte auf dem „Thing“ aufbauen, kann man davon ausgehen dass man mind. auf diese vier Eigenschaften zugreifen kann und genau das ist der ganze Sinn hinter dieser Struktur.
Vor allem Google setzt massiv auf Schema.org, sei es beim Einsatz in der Suche (über die sogenannten Rich-Snippets)…
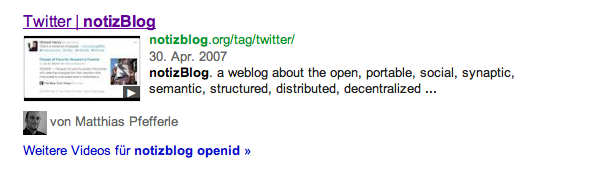
…oder beim Anreichern der, über Google+ oder den +1 Button geteilten Links.
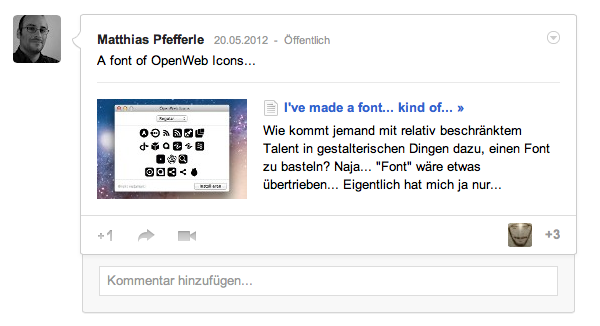
Um das Parsen der Webseiten (zumindest für diese eher einfachen Ausgaben) auf ein Minimum zu reduzieren, ist die Grundstruktur immer gleich und alles darüber hinaus ist reine Kür. Wahrscheinlich werden aber 90% aller Anwendungen mit Titel (name), Beschreibung, Bild und URL auskommen.
Googles Umgang mit Schema.org
Wer seine Seite mit Schema.org auszeichnen möchte, sollte vor allem eines Beachten: Google+ (wahrscheinlich aber auch alle anderen Google Produkte) interpretiert immer das erste im Quellcode verwendete Schema!
Bei meiner ersten Implementierung von Schema.org habe ich mich etwas zu sehr an RSS bzw. Atom orientiert und folgenden Aufbau gewählt: Ein umschließendes Objekt um den Blog zu beschreiben und ein oder mehrere referenzierte Artikel.
<body itemscope itemtype="http://schema.org/Blog">
...
<header id="branding" role="banner">
<hgroup>
<h1 id="site-title" itemprop="name"><?php bloginfo( 'name' ); ?></h1>
<h2 id="site-description" itemprop="description"><?php bloginfo( 'description' ); ?></h2>
</hgroup>
</header>
...
<article itemprop="blogPost" itemscope itemtype="http://schema.org/BlogPosting">
...
</article>
<article itemprop="blogPost" itemscope itemtype="http://schema.org/BlogPosting">
...
</article>
...
</body>Code-Sprache: HTML, XML (xml)Egal ob es jetzt um mehrere Artikel (Startseite) oder nur einen Artikel (Post oder Page) gehandelt hat.
Das hat bei Google+ dazu geführt, dass die notizBlog-Links immer mit dem Titel, der Beschreibung und dem Bild des Blogs und nicht mit denen des Artikels verknüpft wurden. Es ist also gerade für Blogs wichtig, dass das Blog-Schema nur auf den Übersichtsseiten benutzt wird und die Einzelansichten lediglich mit „http://schema.org/BlogPosting“ bzw. „http://schema.org/WebPage“ ausgezeichnet werden.


Schreibe einen Kommentar